Some thoughts on LLM reliability and alignment
I follow Simon Willison for news about all things LLM and he’s generally quite balanced. Even though he has drifted farther and farther toward what might be optimistically called “unquestioning fanboy,” that’s probably an inevitable effect of actually enjoying something. He seems to get a lot of value out of using these tools. I think he might be spending too little time wondering what he would have been producing had he not been grabbing all of the low-hanging fruit that the LLM is delivering to him.
When I read the article AI search engines give incorrect answers at an alarming 60% rate, study says by Benj Edwards (Ars Technica), I found myself wondering why Willison didn’t report on it yet. He’s usually very quick. Is he going to ignore it? Is he not even going to acknowledge it? Even to refute it? Or is he in such a silo that he hasn’t heard of it?
My experience differs quite a bit from Willison’s. The article’s conclusions gibe with mine, in which obvious and completely invalidating mistakes happen a lot. This result squares with my personal experience, in which I am still trying to find a pattern where I incorporate LLM-based tools without losing efficiency to constantly having to correct it.
The article cites from the study that,
“Error rates varied notably among the tested platforms. Perplexity provided incorrect information in 37 percent of the queries tested, whereas ChatGPT Search incorrectly identified 67 percent (134 out of 200) of articles queried. Grok 3 demonstrated the highest error rate, at 94 percent.
“[…]
“The study highlighted a common trend among these AI models: rather than declining to respond when they lacked reliable information, the models frequently provided confabulations—plausible-sounding incorrect or speculative answers. The researchers emphasized that this behavior was consistent across all tested models, not limited to just one tool.”
Given all of that, you would be excused for thinking that the post Hallucinations in code are the least dangerous form of LLM mistakes by Simon Willison would be somewhat more cautious in recommending LLMs, but he writes,
“Hallucinated methods are such a tiny roadblock that when people complain about them I assume they’ve spent minimal time learning how to effectively use these systems—they dropped them at the first hurdle.
“My cynical side suspects they may have been looking for a reason to dismiss the technology and jumped at the first one they found.
“My less cynical side assumes that nobody ever warned them that you have to put a lot of work in to learn how to get good results out of these systems. I’ve been exploring their applications for writing code for over two years now and I’m still learning new tricks (and new strengths and weaknesses) almost every day.”
That’s not been my experience, though. The point that (sane) people are making is that it’s hard to understand the hype and the drive to integrate these goddamned things into everything when they just generate a bunch of slop and wildly incorrect results, not just in code, but in everything.
I recently spoke to a good friend and always-challenging interlocutor who playfully accused me of looking for excuses to not use these tools. I told him that that was unfair, because I felt quite efficient with what I do and I was wondering how much time to invest in getting as much out of these tools as others seem capable of doing. I would like to be even more efficient but, so far, I haven’t seen the benefits. Maybe I suck at it. Maybe I just need to persevere. But I am battling a sneaking suspicion that a lot of other people simply don’t see mistakes.
For example, I saw a picture of Trump supposedly licking Elon Musk’s feet on SNL, where they said that you could tell it had been generated by an LLM because Trump was able to bend over. Hilarious, obviously. But my partner pointed out that it was actually because Musk very obviously had two left feet. We wondered whether that was even medically possible.
So, I searched “two left feet in real life” on DuckDuckGo.
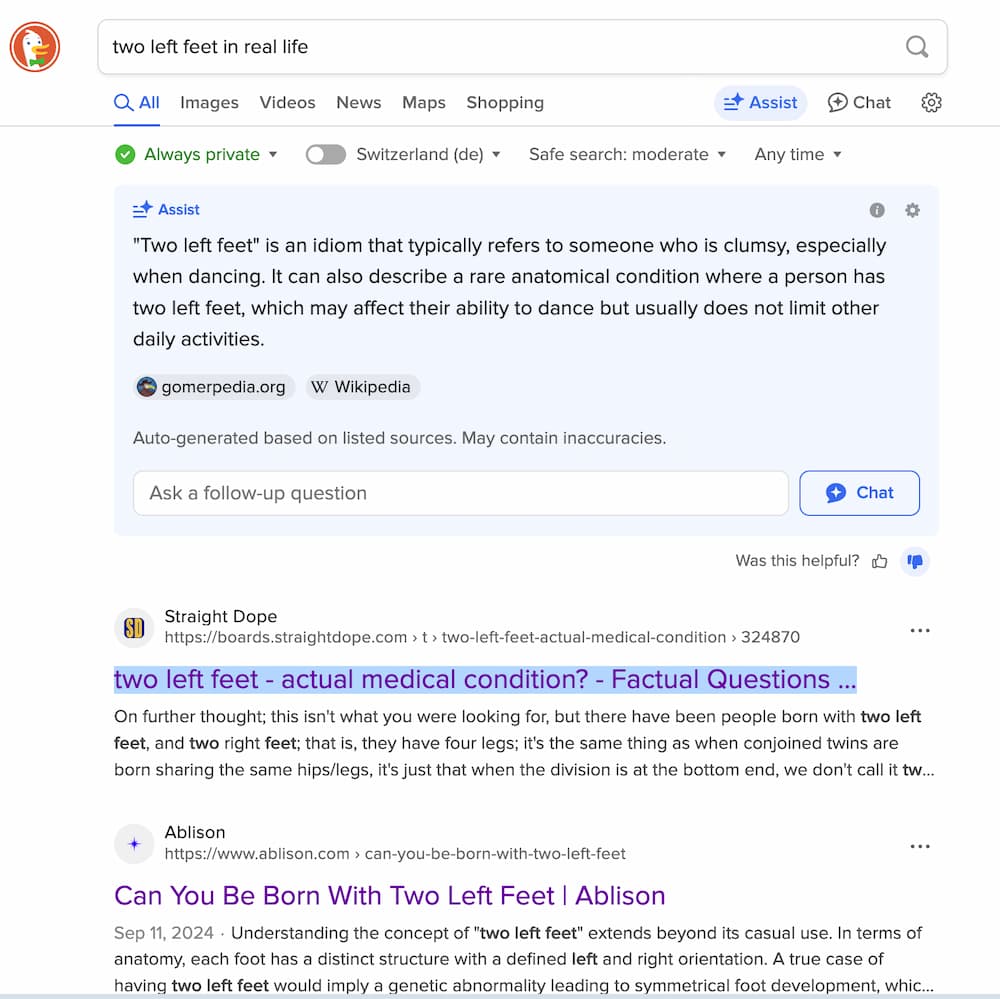 Search results for 'two left feet'
Search results for 'two left feet'
The top result was two left feet − actual medical condition? − Factual Questions … (The Straight Dope), which even highlighted the smartest answer in summary shown inline in the search results,
“On further thought; this isn’t what you were looking for, but there have been people born with two left feet, and two right feet; that is, they have four legs; it’s the same thing as when conjoined twins are born sharing the same hips/legs, it’s just that when the division is at the bottom end, we don’t call it two people.”
The second-ranked answer was from Can You Be Born With Two Left Feet (Ablison), which is just straight-up botshit (AI-generated slop). If you quickly scan the page, you’ll see that it starts off with the factually incorrect “Yes, you can be born with two left feet” but then, further down—after a ton of mediocre, obviously generated, time-wasting, and soul-sucking text—it writes “while being literally born with two left feet does not occur.”
The LLM-generated summary at the top claims to combine two sources—Wikipedia and something called Gomerpedia—to come up with,
““Two left feet” is an idiom that typically refers to someone who is clumsy, especially when dancing. It can also describe a rare anatomical condition where a person has two left feet, which may affect their ability to dance but usually does not limit other daily activities.”
Again, this is not true. It comes from the Gomerpedia link, which is a satire/parody site, claiming to be a “medical encyclopedia” and has an entry for “Two Left Feet”. That entry reads,
“Two left feet is an anatomical condition in which a person is born with a left foot on his or her left leg and a left foot on his or her right leg. Though it may not limit walking or any other activities of daily living, it completely inhabits [sic] a person’s ability to dance, hence the phrase two left feet. Not many people know that it’s a real condition, so take care in making that comment. Interestingly, people with two right feet dance awfully well.”
After re-reading, I’m not sure what to think: is this just a joke site written by someone young or bored? Or is it also an AI-generated site that is now being incorporated into other AI-generated answers?
Here’s Willison’s conclusion,
“I’ll finish this rant with a related observation: I keep seeing people say “if I have to review every line of code an LLM writes, it would have been faster to write it myself!”
“Those people are loudly declaring that they have under-invested in the crucial skills of reading, understanding and reviewing code written by other people. I suggest getting some more practice in. Reviewing code written for you by LLMs is a great way to do that.”
I question whether that’s at all true. It seems to me that the quality of results is eroding and we can’t ignore where this is headed. While Willison seems to benefit from LLM-generated code, it’s unclear to me that he’s not so trapped and invested in this world by now that he literally can’t remember what it was like to program without these tools, or whether he used to produce better or more interesting/sophisticated projects without them. Even if he’s benefitting now, I wonder how much longer he can ride that gravy train before the comparatively rapid onset of enshittification in LLM-based tools catches up to him.
I have been an avid reader of his posts and will continue to be one, but I don’t know whether he’s properly capable of evaluating the pros/cons of LLM-generated code. “Just review it all” isn’t necessarily scalable when there is a lot of slop code to review. You may very well be faster, in the end, writing it yourself. This is something that I think would be worth re-evaluating every once in a while, rather than having anecdotally tested it a long while back and just assumed that things have continued to improve asymptotically.
The other consideration is: is reviewing generated code what you truly want to be doing? I understand that this may be where programming is headed, but it’s a real question that people should ask: just because it’s heading that way, do I have to go with it? Is there room for artisanal code? And is the world of LLM-generated code really here to stay? Or is it going to erode?
I no longer see Willison writing anything about studies that keep coming out, showing code-duplication going way up, and maintainability and legibility going way down. I only see flip responses to “write tests”, which we know no-one does[1], and which will be cheerily constructed by the same LLM that thinks it’s medically possible to have two left feet.
What even is alignment?
The following video was kind-of interesting but—like many people in this field—the presenter seemed to be either completely unwilling to acknowledge or completely ignorant of the fact that in order to “align” something, you have to have some idea of what you’re trying to align it with. Whose principles? Whose mores? To whose benefit?
No Regrets − What Happens to AI Beyond Generative? − Computerphile by Computerphile (YouTube)
While the video itself wasn’t too great, I thought some of the comments on the video were quite insightful,
“Modelling challenges aside, it’s super unclear to me that a meaningful notion of ‘optimal performance’ exists, because the space of all preferences is rarely totally ordered. In reality, you might have several non-comparable and ultimately conflicting behaviors. For example, insurance companies have antipodal interests in providing payouts (the product they promise consumers) and withholding them (upholding their profitability promises to shareholders).”
Honestly, a video that delved deeper into this point would have been much more interesting. It’s an important point because, like, why is this such an amazing tool when it’s just going to be very likely to exacerbate the tension in societally important questions like, “for whose benefit will for-profit insurance companies use this technology? You can only align it one way.”
The following comment continued in this vein,
“The problem with trying to develop systems that are capable of trial and error learning, is that they need to already have an understanding of what goals are appropriate and useful. Unfortunately, we’re currently using reinforcement learning to teach these goals, and are unable to solidly define them. Surely [w]e should be thinking about the right way to make a wish rather than just focusing on how to make the genie.”
That’s what this video made me think, too. The problem isn’t with these technologies. The problem is with the system within which we are building them. We used to have a world that emphasized safety to a nearly ridiculous degree. The understanding was that building a rock-solid trust in a system was worth a tremendous amount, as even a small amount of mistrust—or implication that you would have to balance risk vs. reward—meant that people would avoid doing things that society was trying to encourage.
Nowadays, there seems to be less of an emphasis on safety and more on profit. That’s a problem because it will only ever lead to short-term profit, having cannibalized a trust that will be very costly to build back. The introduction of AIs and seeming dismissal of obvious shortcomings plays right into this. The right people will make much more money if they can sell products and services without having to tinker with safety as long as they used to. It’s the same thing with planned obsolescence—it destroys trust as well as the environment.
Aligning the hardware
Still, I thought the author’s point in the final third was salient: he noted that a lot of work done in the last several years has been in trying to shoehorn new algorithms into existing hardware paradigms like highly generalized CPUs or graphics cards that are more amenable to parallelization of the algorithms than general CPUs are but are still inefficient.
Pushing the algorithms down to hardware is costly and involves much longer turnaround times and development cycles. You have to be sure you’re on a useful path in order to go through the effort of setting up the production pipeline for customized hardware. I wonder how well FPGA can emulate these different configurations or whether those, too, are fundamentally limited in emulating the bandwidth advantages offered by much more highly localizing processing units and memory.
[1] I write tests but I’ve been doing so for a long, long time. I’m an engineer: I considered the question long ago about how the hell do I prove to myself that the products I build meet the my requirements? The answer was tests. For efficiency’s sake, I write automated tests because they’re less error-prone, encourage regression testing, end up using far less time over the medium and long term, aid in coding in the short term, and are just more fun to write than manual testing.↩